

31 oktober 2022
Door Jerrold Stolk (Technology Lead Data & Analytics)
Machine Learning wordt in toenemende mate toegepast binnen bedrijven. Het voorspellen van gedrag of automatiseren van beslissingen – enkele voorbeelden van Machine Learning – heeft grote meerwaarde voor organisaties. Vaak beginnen deze projecten als losse innovatie-initiatieven, maar hoe zorg je ervoor dat de gebouwde modellen beschikbaar en accuraat blijven? Hoe creëer je overzicht in welke modellen in ontwikkeling zijn? En belangrijker nog, hoe faciliteer je Data Scientists zodat zij snel en veilig te werk kunnen gaan? Een volwassen Machine Learning Platform speelt hier een cruciale rol in.
De doelen van dit platform
Steeds meer bedrijven ontdekken de meerwaarde van Machine Learning, en hebben één of meerdere Data Scientists in dienst om modellen te ontwikkelen. Een Data Scientist moet, zoals elke softwareontwikkelaar, ondersteund worden met de juiste tools.
Een Machine Learning Platform heeft als doel om het data science-proces te organiseren en faciliteren. Bij Machine Learning-processen is ondersteuning nodig in zowel de beveiliging van processen, de benodigde rekencapaciteit als het efficiënt ontwikkelen aan modellen (versiebeheer). Deze genoemde termen vatten we samen onder ‘organiseren’.
Bij ‘faciliteren’ kijken we vooral naar het proces. Machine Learning kent namelijk vaste stappen die binnen de organisatie ondersteund moeten worden, waaronder data acquisitie, training en deployment.
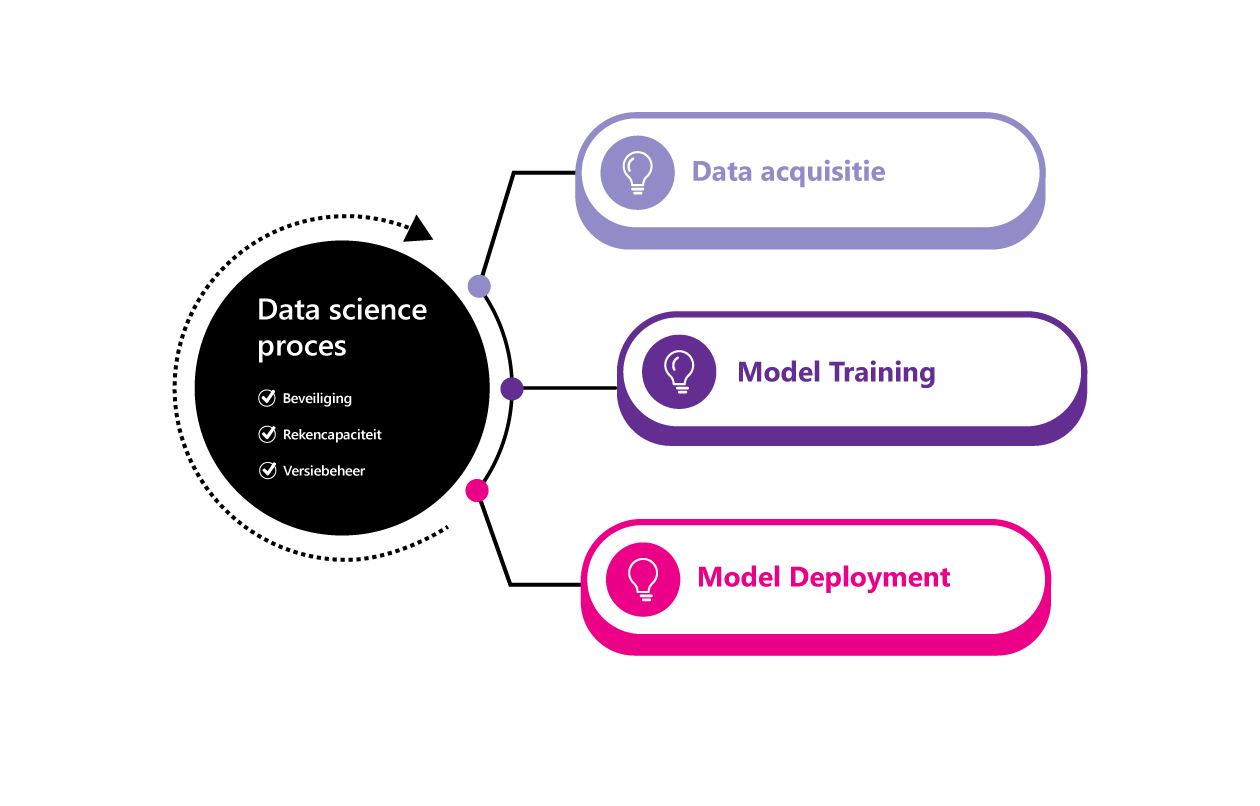
Wat is er nodig voor het organiseren?
Beveiliging
Wie heeft toegang tot welke code, modellen en data? Hoe houden we deze data binnen een beveiligde omgeving? Data science-taken die uitgevoerd worden op niet (geheel) beheerde werkomgevingen, zoals lokale laptops, vormen een grote bedreiging voor verlies van persoonsgevoelige of privacygevoelige data. Een Machine Learning Platform faciliteert een veilige werkomgeving die data afschermt tegen ongewenste toegang.
Rekencapaciteit
Rekencapaciteit is nodig voor twee doelen: het trainen van modellen en het hosten van modellen. De eisen voor beide omgevingen zijn vaak verschillend.
Een trainingsomgeving wordt gebruikt voor het leren van modellen. Dit proces kenmerkt zich door een periode van intensieve rekenkracht die vaak ook geparallelliseerd kan worden. Het trainingsproces kan dan opgesplitst worden en tegelijk op meerdere rekenkernen draaien.
Het hosten van modellen houdt in dat het getrainde model beschikbaar wordt gesteld zodat het inzetbaar is voor gebruik. Hierin zijn twee categorieën te onderkennen:
Batch Inference
Sommige Use Cases zijn zo ingericht dat een berekening periodiek wordt uitgevoerd voor een grotere hoeveelheid data. Denk hierbij aan het weermodel van KNMI dat acht keer per dag berekend wordt. Hier is, net als bij het trainen van modellen, een intensieve rekenkracht nodig gedurende een gelimiteerde periode.
Real-Time Inference
Andere Use Cases kenmerken zich door het real-time berekenen van uitkomsten. Denk hierbij aan dynamische prijzen die direct berekend worden op basis van iemands kenmerken en gedrag. Dit kenmerkt zich door een continue beschikbaarheid van rekenkracht, met de capaciteit om piekbelasting op te vangen. Hier wordt in de praktijk vaak een containeroplossing voor gebruikt, waarbij het mogelijk is dynamisch rekencapaciteit toe te voegen.
Versiebeheer
Een data science-proces is iteratief. Het is géén lineair proces waarbij je van tevoren de details plant en vervolgens uitwerkt. Het is wél een proces van ontdekken, bijsturen, aanpassen en testen. Het bijhouden van versies is hierbij essentieel en dit bijhouden gebeurt op twee gebieden:
Versiebeheer op code
Een Data Scientist schrijft veelal code om een model te trainen. Daarnaast zal er code geschreven worden om het aanroepen van modellen te stroomlijnen (model inferencing). Versies van deze code moeten bewaard kunnen blijven, zodat het altijd mogelijk is om terug te gaan naar een vorige versie.
Versiebeheer voor modellen
Elke keer dat een model getraind wordt, heeft het nieuwe kenmerken. Wanneer het model verder wordt bijgesteld moeten de scores vergeleken worden, en om dit te kunnen is het noodzakelijk terug te kunnen gaan naar een eerdere versie van een model. Ook hiervoor is versiebeheer nodig.
Nu we gezien hebben hoe een Machine Learning Platform organiseert, is het tijd om te kijken hoe het data science-proces gefaciliteerd wordt.
Welke fasen moeten ondersteund worden?
Data acquisitie
Juiste data is essentieel voor een goed werkend model. Data acquisitie omvat het verkrijgen en beschikbaar stellen van deze data voor Machine Learning-doeleinden. Een Machine Learning Platform biedt hierin een faciliterende rol. Datasets moeten vindbaar en van goede kwaliteit zijn om direct in Machine Learning-processen gebruikt te kunnen worden. Als toevoeging is een dataplatform, de rol van Data Engineers en goede samenwerking tussen verschillende disciplines ook van belang in dit proces.
Model Training
Model Training is de centrale stap in het Machine Learning-proces. Deze stap resulteert in een model dat gevalideerd, getest en gepubliceerd kan worden. Om dit uit te voeren heeft een Data Scientist een breed scala aan tools en frameworks nodig. Denk aan ontwikkelomgevingen in Python of R en deep learning frameworks zoals PyTorch. Een Machine Learning Platform biedt deze omgeving aan. Deze tools en frameworks kunnen aangeboden worden in een GUI, in een beheerde omgeving of in een gekoppelde, eigen omgeving.
In de praktijk wordt het duidelijk dat een Data Scientist de voorkeur geeft aan omgevingen die flexibel in te richten zijn, met de open source tools en frameworks om de Model Training uit te voeren. Het platform maakt het hierbij mogelijk om het model training–proces te registreren en op te volgen.
Model Deployment
Wanneer een model getraind en gevalideerd is, is het moment daar om het in werking te zetten. Het resultaat hiervan is dat men een model heeft dat repeterend ingezet kan worden. De benodigde rekenstap voor het repeterend inzetten verschilt voor Batch Inferencing en Real-Time Inferencing.
Voor beide omgevingen is een proces nodig om de versies op te volgen en nieuwe versies uit te rollen. Een Machine Learning Platform helpt bij het opvolgen en automatiseren van dit proces zodat nieuwe versies met een druk op de knop opgeleverd kunnen worden. De uitgerolde versies zijn na deployment te monitoren op performance (is het model online) en op model-fit (sluiten de resultaten aan op de waarheid). Beide waarden kunnen een reden zijn om aanpassingen te maken. Dit maakt de bovenstaande stappen een iteratief en repetitief proces.
Met een Machine Learning Platform wordt de kracht van jouw Data Scientists en Engineers volledig benut. Zonder het gebruik van een dergelijk platform loopt jouw organisatie risico’s rondom data beveiliging en de transparantie van jouw Machine Learning-processen.
Benieuwd naar de toegevoegde waarde van Machine Learning voor jouw organisatie, of welke innovatieve oplossingen data science je kunnen bieden? Wij helpen je graag verder! Neem contact op met Jerrold Stolk, Technology Lead op het gebied van Data & Analytics bij Motion10.
Neem contact op